

TL;DR — What Ling-1T Is and Why It Matters
Ling-1T is Ant Group’s trillion-parameter language model that blends scale with efficiency. It uses a Mixture-of-Experts (MoE) design, meaning not every parameter works at once; only the most relevant “experts” are activated for each task. This smart routing gives Ling-1T massive reasoning power without wasting compute.
Quick highlights:
- What Ling-1T is: A trillion-parameter Mixture-of-Experts model built by Ant Group, designed to combine vast capacity with faster, more efficient performance.
- Benchmark power: Early results show strong performance on AIME math reasoning and coding tasks, ranking among top global models in these categories.
- Open-source impact: By releasing Ling-1T openly, Ant Group gives researchers and enterprises a new foundation for experimentation, collaboration, and large-scale AI innovation.
Ant Group’s Ling family and the context behind Ling-1T
From the moment Ant Group announced its trillion-parameter model, the term Ant Group Ling-1T started showing up in headlines. But this release didn’t come out of nowhere—it’s part of a broader strategy the company has been refining for years.
A quick history of the Ling family
Ant Group’s journey into large language models escalated visibly in 2025. On October 9, 2025, Ant Group formally unveiled Ling-1T, describing it as an open-source, trillion-parameter general-purpose model. Business Wire+2Yahoo Finance+2
The announcement also positioned Ling-1T as the flagship “Ling” series model: a non-thinking (so to speak) Mixture-of-Experts model family. Business Wire+1
Behind that announcement, Ant Group has been building out a naming and categorisation strategy for its AI model ecosystem:
- Ling series: the non-thinking LLMs (large language models) built for general tasks. Business Wire+1
- Ring series: what Ant calls the “thinking” models—designed for deeper reasoning and complex decision-making. Business Wire
- Ming series: multimodal models (text, image, audio, video) that extend beyond pure language. Business Wire+1
In short: the Ling family is not just a single model—it’s the first tier of a broader, layered architecture of AI models from Ant.
Why a fintech giant is investing in open large-language models
It might seem unusual that a company best known for digital payments is also building cutting-edge language models. But the logic behind Ant Group’s move becomes clear when you connect the dots:
- Data access & scale: With its Alipay platform and other digital finance services, Ant Group has access to massive transactional, behavioural and service-oriented data sets—an asset when training large language and reasoning models.
- Productisation potential: These models can power all kinds of embedded services—from smarter customer-service bots, document processing in lending/insurance, fraud detection, to multilingual support for global payments. The open-source release of Ling-1T signals that Ant sees a role for these models beyond internal R&D.
- R&D and infrastructure leadership: By open-sourcing a trillion-parameter model, Ant Group positions itself as an infrastructure player in the machine-intelligence ecosystem. According to their CTO, “At Ant Group, we believe … AGI should be a public good—a shared milestone for humanity’s intelligent future.”
- Competitive differentiation amid hardware constraints: Some reporting suggests Chinese tech firms—with restricted access to certain advanced chips—are emphasising algorithmic innovation over raw hardware alone. Ant’s move with the Ling family fits this pattern. TechWire Asia+1
In sum: Ant Group’s embrace of large-language models is less a curiosity and more a strategic gambit—leveraging its fintech roots and user base to build next-gen AI capabilities.
Ling-1T architecture explained: trillion parameters, Mixture-of-Experts, and active parameters
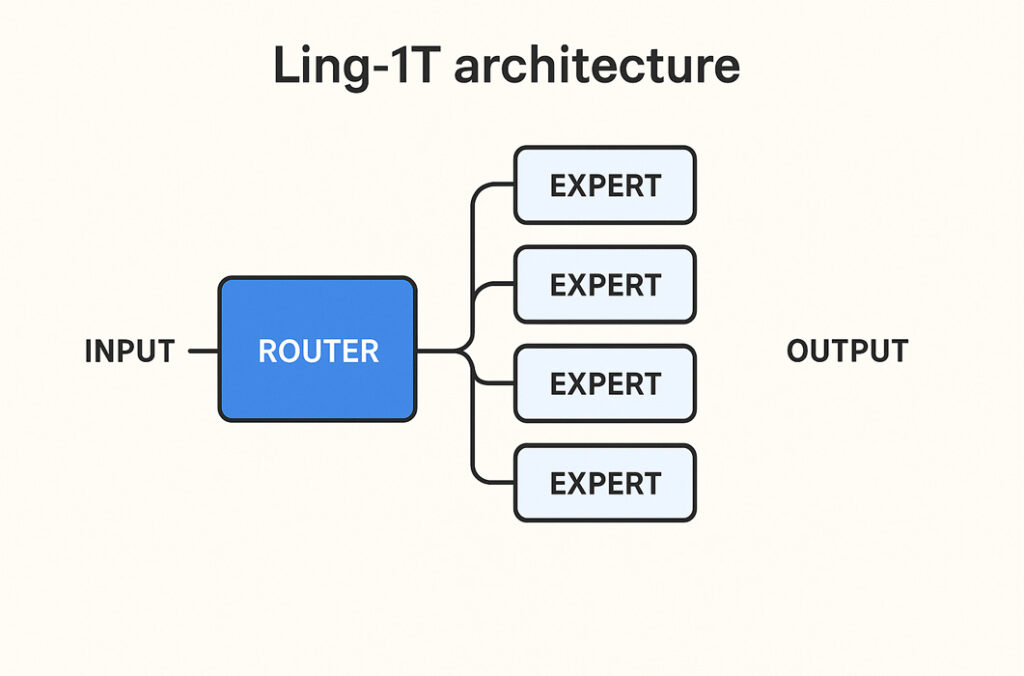
The Ling-1T architecture is Ant Group’s most ambitious language model design to date — a trillion-parameter system built on the Mixture-of-Experts (MoE) approach. In simple terms, it combines the capacity of a huge model with the efficiency of a smaller one. The idea is clever: instead of using every parameter for every task, Ling-1T activates only the “experts” it needs at that moment — just like calling a few specialists instead of an entire company to solve one problem.
1. Model type — Mixture-of-Experts (MoE)
At its core, Ling-1T architecture uses a Mixture-of-Experts design.
Here’s how that works in plain English:
- Imagine a giant team of experts, each skilled in a particular topic — math, language, coding, logic, etc.
- When a question comes in, the system doesn’t ask everyone to answer. It routes the question to just a few relevant experts.
- The result? The model can be enormous in total capacity (1 trillion parameters) but still efficient to run — since only a small part is “awake” for each token.
According to the official model card, Ling-1T contains around 1 trillion total parameters, with roughly 50 billion active per token.
This means for any given input, only about 5 % of the total parameters are actually used — a massive improvement in compute efficiency.
In practice, this structure allows Ling-1T to think “wide” (many experts available) but act “light” (few experts active), making it both powerful and scalable.
2. Active vs Total Parameters — Sparse activation made simple
In most traditional models, every parameter is activated during inference — that’s called a dense model. But in the Ling-1T architecture, parameters are sparsely activated.
Here’s the simple distinction:
- Total parameters: the full number of weights the model could use (≈ 1 trillion).
- Active parameters: the number actually used per token (≈ 50 billion).
This “sparse activation” approach means the model runs faster, uses less energy, and can fit into existing hardware more easily.
It’s like having a library of one million books — you don’t read all of them at once, only the few relevant ones each time.
This efficiency gives Ling-1T an advantage over dense trillion-parameter models, which would otherwise require impractical compute power for every task.
3. Training data & compute design
Building the Ling-1T architecture wasn’t just about size; it was about smart engineering. Ant Group reports that the model was trained on more than 20 trillion high-quality tokens, with data specially curated for reasoning, language comprehension, and code.
Key design points include:
- FP8 mixed-precision training — helps reduce memory load and training time without sacrificing accuracy.
- 128K token context window — enables Ling-1T to handle very long documents or conversations without losing context.
- Advanced routing and balancing — ensures experts are evenly trained and activated, avoiding “lazy experts” (a common MoE issue).
- Evo-CoT (Evolutionary Chain-of-Thought) step — an additional reasoning fine-tuning process that improves multi-step logic consistency.
Together, these make Ling-1T one of the most compute-efficient trillion-scale models ever released.
4. Comparison: How Ling-1T fits among other MoE models
To understand its place in the ecosystem, here’s how Ling-1T architecture compares with other recent MoE systems:
| Model | Total Params | Active Params | Key Focus | Notes |
|---|---|---|---|---|
| Ling-1T (Ant Group) | 1 T | ~50 B | Reasoning, coding, enterprise apps | FP8 + Evo-CoT + open-source |
| Mixtral (Mistral) | 12.9 B | ~2 B | Multilingual, efficient | Open weights; smaller MoE |
| DeepSeek V2 | 671 B | ~37 B | Reasoning, planning | Commercial research model |
| GPT-4 MoE (unofficial) | ~1.8 T | ~40 B | Multimodal tasks | Proprietary |
What sets Ling-1T apart is balance — a trillion-parameter model that’s still open-sourced and practical for real-world use.
For enterprises, this means a model powerful enough for reasoning and data analysis — but efficient enough to deploy on commercial infrastructure.
5. Why Ling-1T architecture matters
The launch of Ling-1T isn’t just another “bigger is better” story. It shows that scaling smartly — through expert routing and sparse activation — may be the future of large language models.
Because of its design, Ling-1T can:
- Deliver high reasoning and math accuracy while keeping inference costs lower.
- Handle long-form content (up to 128K tokens).
- Offer enterprise-ready flexibility — combining open access with scalable efficiency.
In short, the Ling-1T architecture redefines how trillion-parameter models can be built: not by brute force, but by thoughtful engineering.
How Ling-1T performs: benchmarks, math reasoning, and coding tests
5. Opening summary
The headline of the Ling-1T benchmarks is simple: the model from Ant Group achieved a 70.42% accuracy on the 2025 American Invitational Mathematics Examination (AIME) benchmark — a competition-level math test — while also showing strong results on coding and reasoning tasks. OrionAI+3Business Wire+3AI News+3
Below, we unpack what those numbers really mean, how they were measured, and how Ling-1T stacks up against peers.
5. What the key benchmarks measure
AIME (American Invitational Mathematics Examination): This is an elite mathematics competition for high-school students in the U.S., designed to test deep problem-solving skills rather than simple arithmetic. A strong score here suggests a model can handle multi-step reasoning, logic flows, and less-structured math problems.
In its announcement, Ant Group states Ling-1T achieved 70.42% accuracy on the 2025 AIME benchmark, using “an average cost of over 4,000 output tokens per problem”.
Coding and software-engineering benchmarks: According to the model card and third-party commentary, Ling-1T was evaluated on code generation, debugging and UI/UX front-end generation tasks. For example, it achieved leading performance on an open-source “ArtifactsBench” for front-end generation. Medium+2Hugging Face+2
Reasoning & tool-use benchmarks: The model card claims around ~70% tool-call accuracy on the “BFCL V3” tool-use benchmark with only light instruction fine-tuning.
5. Reported numbers & caveats
Here are some of the reported highlights for Ling-1T benchmarks:
- 70.42% accuracy on AIME-25.
- Efficient cost: “an average cost of over 4,000 output tokens per problem” on AIME. AI News+1
- The model card notes a 1T/50B parameter MoE architecture and states “emergent reasoning and transfer capabilities” after scaling.
- On front-end generation / UI reasoning (ArtifactsBench) it reportedly ranked first among open-source models.
Caveats you should mention in your blog:
- These numbers are claimed by Ant Group (and related model-card authors); independent third-party verification is still limited. Towards AI+1
- Benchmarks like AIME test a specific skill (math competition style), which is not the same as general conversational or real-world deployment.
- The “average cost of over 4,000 tokens” is a measure of output length, not necessarily latency or inference cost in a live system.
- Many benchmarks are zero-shot/few-shot setups or require fine-tuning; the exact conditions matter for comparison.
- Benchmarks alone don’t guarantee safety, robustness, alignment or performance on unseen tasks.
Why Ant Group open-sourced Ling-1T — benefits for research and the security & ethics trade-offs
When Ant Group announced the open-source Ling-1T model, it wasn’t just releasing another technical artifact — it was making a statement about how large-scale AI development should evolve. The company published the trillion-parameter model’s architecture, weights, and detailed training methodology, positioning it as one of the largest open models ever shared publicly. (BusinessWire, Oct 9 2025)
This move sparked debate across the AI world: is open access to trillion-scale models a leap forward for science — or a risk multiplier for misuse?
1. The benefits of open-sourcing Ling-1T
Ant Group’s decision carries several upsides for both the research community and industry adopters:
- Reproducibility and transparency — By releasing model weights and training recipes, researchers can verify Ant Group’s claims, rerun experiments, and build on the work instead of guessing from opaque papers.
- Faster community innovation — Open models encourage independent teams to develop fine-tuned variants, add safety layers, or test new architectures. The open-source Ling-1T model could become a foundation for future reasoning or enterprise-grade language models.
- Enterprise adoption and cost savings — Businesses can integrate the model locally for data-sensitive applications such as document intelligence, chatbots, and analytics, without sending information to external APIs.
- Faster debugging and benchmarking — Public scrutiny often leads to rapid identification of weaknesses and bias issues, helping developers harden future releases more quickly.
- Public-good positioning — Ant Group’s CTO stated that “AGI should be a public good — a shared milestone for humanity’s intelligent future,” framing the release as a step toward collaborative AI progress.
2. Risks and trade-offs of open access
Still, making a trillion-parameter model public isn’t without concern. Experts have highlighted a few potential downsides:
- Dual-use risk — The same capabilities that help research can enable malicious uses such as automated phishing, disinformation, or synthetic identity generation.
- Model theft and repackaging — Once the weights are public, cloned versions can circulate without oversight, possibly under different names and safety layers.
- Amplified hallucinations and misinformation — Open-source models, when fine-tuned incorrectly, can become more prone to producing false or misleading content.
- Regulatory exposure — Governments may scrutinize large open models more closely, especially under forthcoming AI-safety and export regulations in the EU and China.
- Security oversight challenges — Open models make it harder to control who uses them or to audit misuse across jurisdictions.
Ant Group’s release notes acknowledged these challenges, stressing the need for responsible use and continued research on alignment and misuse detection.
3. Governance and responsible-release practices
Industry observers point to several ways companies can balance openness with accountability. For the open-source Ling-1T release, Ant Group highlighted its staged approach — starting with model weights and documentation while continuing to evaluate downstream use cases.
Common governance practices now discussed across open-model communities include:
- Staged release — Gradually releasing capabilities while monitoring how the ecosystem uses them.
- Watermarking and output detectors — Embedding subtle signatures to trace generated content and prevent malicious use.
- Red-team evaluations — Running pre-release stress tests to find vulnerabilities in reasoning, safety, and misuse.
- Transparent licensing — Clear usage terms that define commercial vs. research rights.
These strategies are increasingly seen as baseline safeguards for powerful open models.
Ling-1T FAQ
1. What is Ling-1T?
Ling-1T is a trillion-parameter large language model developed by Ant Group as part of its “Ling” AI series. It was announced on October 9, 2025, and is designed for advanced reasoning, multilingual understanding, and enterprise-scale deployment.
2. Who built Ling-1T?
Ant Group Ling-1T was built by the Hangzhou-based fintech and AI company Ant Group, best known for Alipay. The model was developed by the company’s Ling Research division, which also produced earlier models such as Ling, Ring, and Ming.
3. Is Ling-1T open-source?
Yes — open-source Ling-1T was released with model weights, architecture details, and documentation for research and enterprise adaptation. Ant Group published the model to encourage transparency, reproducibility, and innovation in AI development. Source: Ant Group AI Blog
4. How many parameters does Ling-1T have?
Ling-1T parameters total approximately 1 trillion, making it one of the largest publicly shared models to date. It uses a Mixture-of-Experts (MoE) architecture, activating only part of the network for each query — allowing high efficiency despite massive scale.
5. How does Ling-1T compare to GPT-5?
In early benchmarks, Ling-1T vs GPT-5 results show competitive reasoning and math accuracy. Ling-1T reportedly achieved around 70.42% on AIME, compared to GPT-5’s 74% range, though direct comparisons vary by test setup. While GPT-5 leads in creative generation, Ling-1T performs strongly in structured reasoning and enterprise reliability.
6. Can I run Ling-1T locally?
Running Ling-1T locally is technically possible but requires significant hardware — think multiple A100 or H200 GPUs with large-scale memory. For most users, Ant Group provides lighter variants and APIs for deployment through its developer portal and Alipay-integrated services.
7. What are Ling-1T’s main use cases?
Common Ling-1T use cases include:
- Multilingual customer support and chatbots
- Financial document summarization
- Code generation and RPA (robotic process automation)
- Research and data analysis within enterprise AI stacks
Because it’s open-source, developers can fine-tune Ling-1T for custom applications across education, fintech, and customer engagement.
8. Is Ling-1T safe to use for finance?
Ling-1T safety was a key focus in its release. Ant Group says the model includes safety filters, bias detection, and financial domain fine-tuning. However, as with any open LLM, risk depends on deployment — enterprises should apply strict content moderation and human-in-the-loop validation before using Ling-1T in regulated financial contexts.
Final Thought: Why Ling-1T matters for the next wave of AI innovation
Ling-1T isn’t just another large model; it’s a signal that the future of artificial intelligence won’t be owned by a handful of Western labs. Ant Group’s trillion-parameter leap shows how open collaboration, transparency, and research sharing can balance power across the global AI ecosystem.
By releasing Ling-1T openly, Ant Group has invited researchers and enterprises everywhere to test, refine, and responsibly scale frontier AI — not behind closed doors, but in the open. It’s a reminder that the next breakthroughs may come from anywhere, as long as innovation stays grounded in ethics, openness, and real human purpose. 💫
🔗 Explore More from E-Vichar
Want to dive deeper into smart tech, tools, and modern living? Check out these expert-curated guides and insights:
- 💡 Best AI Productivity Tools for Smarter Work — Discover top AI tools to simplify your workflow and save time.
- 🤖 Best Free Chatbots in 2025 — Top Picks Guide — Find the most powerful and user-friendly chatbots available this year.
- 🌿 What Is Minimalism? A Simple Living Guide — Learn how to declutter your digital and personal life for more focus.
👉 Follow us on Facebook: E-Vichar Official Page — stay updated with the latest insights, tools, and trend breakdowns.


